I'm Bret,
a data scientist.

I’m an aspiring Data Scientist with over 7 years of experience in variety of industries. I am a highly motivated individual devoted to solving problems and continued learning. I utilize a variety of analytical techniques to develop creative solutions to challenging problems and make intuitive decisions and effectively communicating to all audience types. I am experienced in Python, R, Data Cleaning, Data Visualization, and Machine Learning.
I started my journey by obtaining my undergraduate degree in biochemistry from Northern Illinois University. After graduating, I began working in health, safety, and environmental for a worldwide engineering, procurement, and construction company where I collected data in relation to incidents, employee exposures and waste. The data was analyzed to identify trends which led to campaigns to enhance employee awareness and updated policies to protect workers as well as reduce project costs. I also aided in generating and presenting safety training and presented data trends in weekly project meetings.
I then moved into the hospitality industry working for another worldwide company where I took a role as a scheduler ensuring employees were scheduled in accordance with labor laws and agreements. This role allowed me to analyze shift data and identify areas of improvement reducing expenditures. Seeing all the data that was available in this role, I decided to continue my education and started my master’s degree from Bellevue University in data science.
When I am not working on projects or studying, I spend time with my family or tying flies for my next fly-fishing adventure.
I am most proficient with Python and most of my projects start here. I am also familiar with R and Visual Basic.
Most of my time during a data science project is spent cleaning and exploring data. I constantly use these to uncover patterns and test hypothesis through summary statistics.
Being able to visualize data is my favorite part of a project. I am experienced with Matplot lib and Ggplot2. I have also used Seaborn and Plotly in my projects depending on visualization needs.
I am most comfortable working with Scikit-learn for building machine learning models. I have used this for many projects and am familiar with many algorithms. When working with neural networks, TensorFlow is my preference.
For databases, I am trained in SQL and PostgreSQL. I have also worked in MySQL in the past.
Organization and version control are important in any project. I always build a project using Git or GitHub for this reason.
Utilizing an integrated development environment (IDE) is an important aspect to improve code maintaniability. I prefer to use JupyterLab or ATOM for my Pyton IDE and Rstudio for R. I have also used Pycharm for past projects.

Sales forecasting is an important aspect of determining if the company is meeting their goals, setting budgets and determine if sales promotions are needed. The goal of this project was to forecast the next 7 days after the series data ended. A naive baseline and an ARIMA model were compared with the ARIMA model performing better.
Documentation
Various models were used to predict loan amount for online loan applications. The random forest model with 7 trees performed the best with the lowest mean squared error and highest r-squared values.
Documentation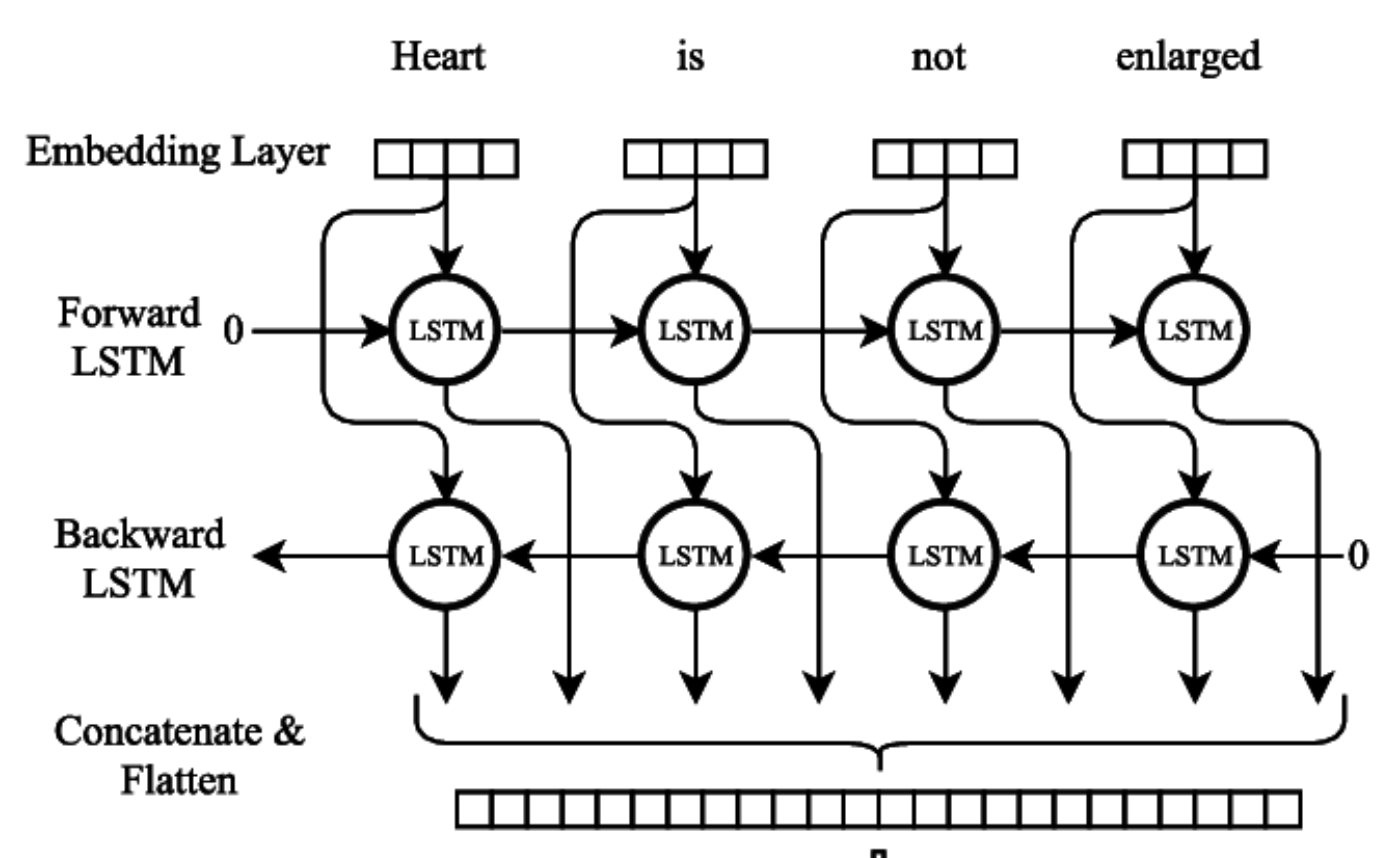
Drug reviews from Drugs.com were converted into a vector representation and feed into a bidirectional long-shhort term memory recurrent neural network. The model accuracy was 60% compared to 26% for the baseline randomly predicting the highest occurring condition.
Documentation
Airline and automobile fatality datasets were used to show that airline travel is still safer than automobiles despite an increase in unfortunate events. This project is still in progress.
Documentation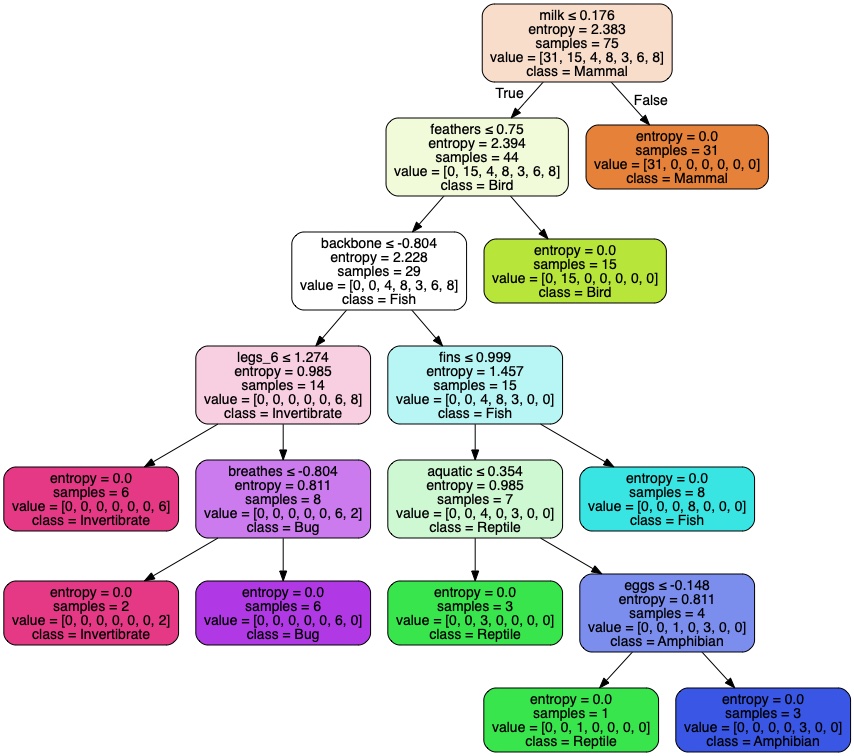
Traits of animals were used to create a decission tree used to classify the animal into mammal, bird, reptile, fish, invertibrate, bug or amphibian.
Documentation
In the era of streaming services, having the ability to recommend movies thhe client may be highly interested in is vital. This project is designed to present the top 10 movies based on distance to the selected movie using a k-Nearest Neighbors model on multiple user ratings.
Documentation
Product reviews of women's clothing were analyzed to determine if the review was positive or negative based on a list of predefined words. The final decision was made by summing the positive and negative values, which may have also ended with a neutral review classification.
Documentation

Application programming interfaces, API's, for OpenWeatherMap and Twitter were used to obtain data and used to build databases for future analysis.
Documentation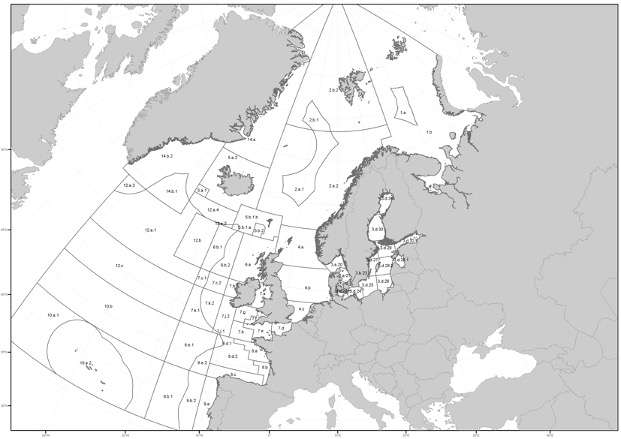
Historical North Atlantic salmon catch data from the International Counsil for the Exploration of the Sea was analyzed to determine the optimal location to commercially fish for Atlantic salmon.
Documentation
Data comes in many different formats and very rarely is ready to be used in a model without processing. This project performed cleaning and transformation to a dataset to prepare it for machine learning and additional analysis.
Documentation